The 66-Second AI Rescue
I sabotaged my production database and my AI fixed it in 66 seconds... without waking up any humans. Here's how. 🤖⚡
At 2:56 AM my database started choking. By 2:57:06 AM it was fixed. The crazy part? I was asleep. My AI was awake. I've been obsessed with one problem: What if infrastructure could heal itself? So I built LogSentinel — a Python-based AIOps platform that:
- Monitors every metric in real-time
- Feeds failures to an AI (Gemini 1.5 Flash)
- Executes AI-recommended fixes automatically
- Sends Discord alerts every step of the way
The Real Test
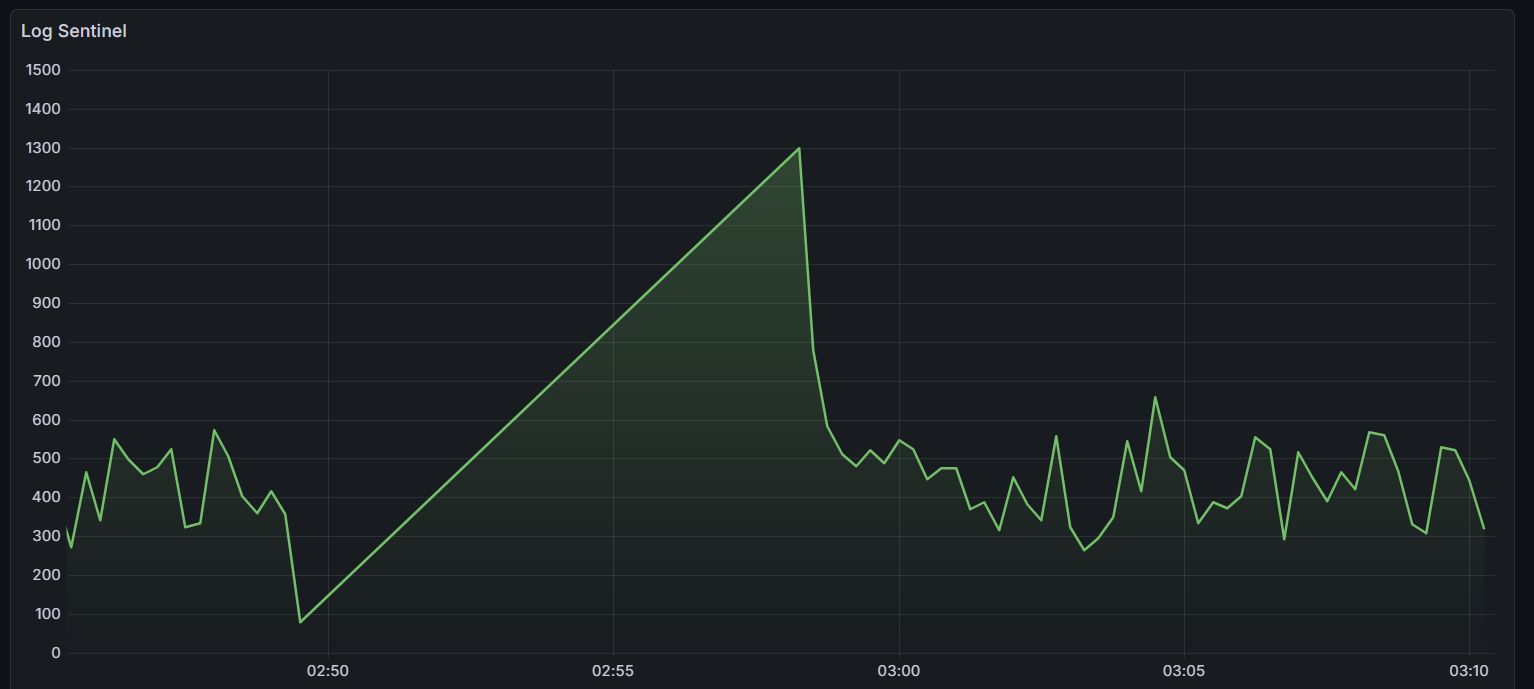
I sabotaged the database myself, intentionally triggering a queue overflow expecting chaos. Instead, Grafana showed a quick spike, a dip, and a baseline recovery in 70 seconds total.
What actually happened behind the scenes:
- Phase 1: Yellow Alert (0 seconds) - My monitor detected queue overflow and sent: "🟡 Issue Detected"
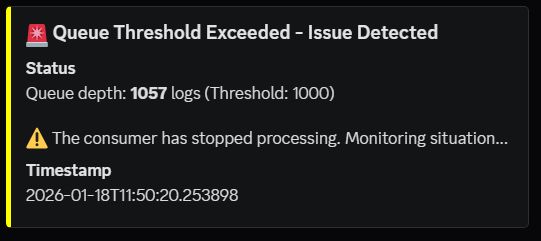
- Phase 2: Red Alert + AI Analysis (60 seconds) - Still failing. The system escalated by capturing container logs, sending them to Gemini for analysis, and receiving: "Root cause: Consumer process stopped. Fix: Restart service." Sent Red Alert: "🔴 AutoSRE Investigating"
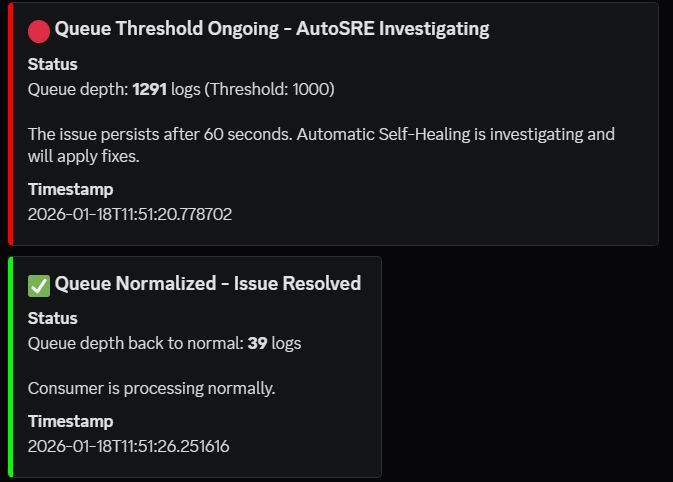
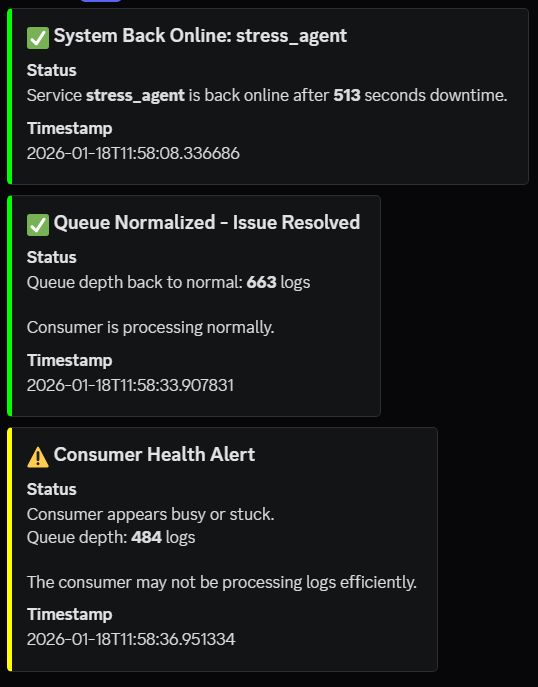
- Phase 3: Execute Fix (65 seconds) - All queued requests processed. Services back online. Discord: "✅ AutoSRE Fix Applied"
The Metrics That Matter
- Traditional Approach: 3AM page alert + Check Datadog (2 min) + SSH into server (1 min) + Diagnose issue (3 min) + Restart service (1 min) + Verify recovery (2 min) = ~9 minutes downtime
- My AI Approach: AI detects issue (2 sec) + AI analyzes logs (60 sec) + AI fixes automatically (4 sec) = ~66 seconds downtime
That's ~8 minutes saved (95%). Per incident. Every day.
This isn't theoretical DevOps thinking—it's the present. Every second of downtime costs money, trust, and SLA penalties. The question isn't "Can AI fix production issues?" anymore. It's "Why isn't every SRE team deploying AI-powered remediation?"
The Brains of the Operation
Here's the alert escalation logic—the heart of the system that enables intelligent escalation instead of dumb alerting:
if queue_depth > CRITICAL_THRESHOLD:
if not alert_sent:
# Phase 1: Yellow alert
discord.send("🟡 Issue Detected", color=YELLOW)
alert_sent = True
trigger_time = time.time()
elif time.time() - trigger_time > 60:
# Phase 2: Red alert + AI analysis
logs = fetch_container_logs()
analysis = gemini.analyze_logs(logs)
remedy = analysis['remedy']
# Phase 3: Execute fix
subprocess.run(["docker-compose", "restart", "consumer"])
discord.send("✅ Fix Applied", color=GREEN)
Stack: Python, Docker, Prometheus, Grafana, Gemini 1.5 Flash, Discord