Breaking Production on Purpose
"Reliability" isn't about never failing. It's about how fast you recover when you do fail.
Today, I moved from simple "Monitoring" to Chaos Engineering. Instead of crossing my fingers and hoping my Redis queue stays alive, I wrote a Python script (chaos.py) to actively hunt down and KILL the container during peak load. The system fixed itself in exactly 45 seconds.
The Experiment
- The Attack - My script disconnected the
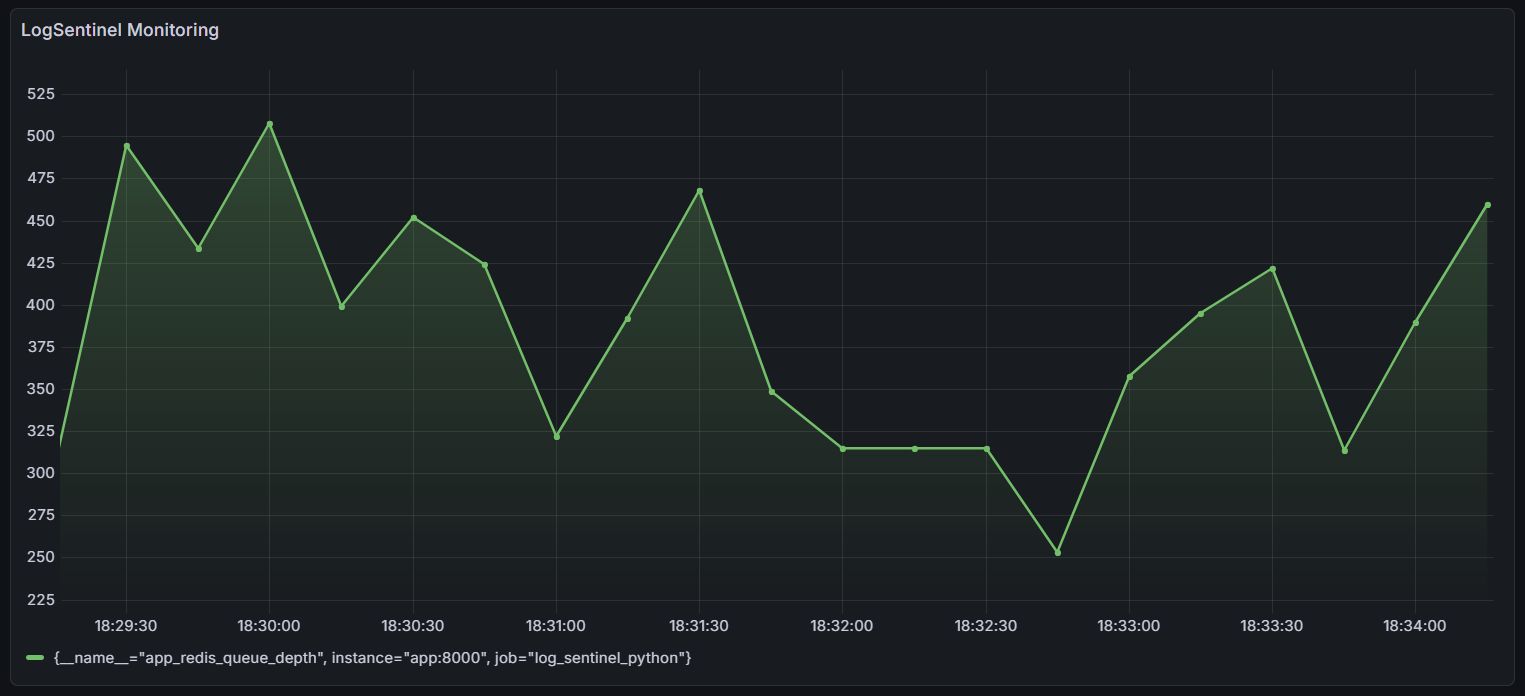
redis_storecontainer at 18:32. - The Impact - The Grafana snapshot below shows the queue depth flatlining. The heartbeat stopped.
- The Resilience - I sat back and watched. The orchestration layer (Docker) detected the health check failure and automatically spun up a fresh instance.
- The Result - System back online in 45 seconds with zero human intervention.
Key Takeaway
Why do this? Because if you wait for a real outage to test your recovery strategy, it is already too late.
Stack: Python, Docker, Redis, Grafana