Silence is Not Reliability
Silence is not Reliability, it is just a broken alarm.
Day 3 of my SRE Sprint: The Scream Test. For the last two days, I stared at Grafana dashboards to spot failures. But in a real production environment, you can't stare at a screen 24/7. Today, I built the "Voice" of the system.
The Stack
- Prometheus - Detects the heartbeat stop.
- Alertmanager - Routes the panic signal.
- Discord Webhooks - The pager that wakes me up.
The Scenario: I killed my Python App container.
- T+10s - Prometheus flagged InstanceDown as Pending.
- T+20s - Alert changed to FIRING [Red State].
- T+30s - My phone buzzed with a Discord notification from the server.
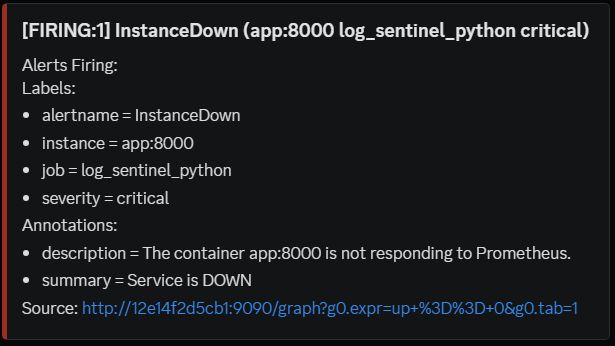
The Lesson
Reliability isn't just about keeping servers up, it's about reducing the Time To Detect (TTD). If my server crashes in the forest and no one gets a ping, did it really crash? (Yes, and the customers are angry).
Stack: Prometheus, Alertmanager, Discord, Python